论文译文
外文原文题目:WAV2LETTER++: THE FASTEST OPEN-SOURCE SPEECH RECOGNITION SYSTEM
中文译文题目:WAV2LETTER++,最高效的开源语音识别系统
原文作者: Vineel Pratap, Awni Hannun, Qiantong Xu, Jeff Cai, Jacob Kahn, Gabriel Synnaeve, Vitaliy Liptchinsky, Ronan Collobert
所属单位:Facebook AI Research
译文作者:岳昕阳
所属单位:重庆劳格科技有限公司
原文发表于:Cornell University网站
https://arxiv.org/abs/1812.07625
版权所有 非授权谢绝转载
摘 要
这篇论文将会介绍当前最高效的基于深度学习的语音识别架构——wav2letter++。wav2letter++完全由C++语言编写并使用了能最大化提升效率的ArrayFire张量库。本文将介绍wav2letter++系统的整体框架与设计并将其与其他现存常见的主要的开源语音识别系统相比较。比较后可以发现在一定情况下wav2letter++比其他已经经过优化的端到端语音识别神经网络训练速度快超过两倍以上。我们同样会展示在对一亿个参数的模型进行训练测试时,wav2letter++的训练次数最多线性扩展到了64GPU。高性能结构可以加快迭代速度,而迭代速度很多时候又是直接关乎研究与训练新的数据库或任务模型的成功率的重要参数。
关键词:语音识别,开源软件,端到端
1. 介绍
随着大众对于自动语音识别(automatic speech recognition,ASR)技术关注的不断加强,在众多开源软件社区中语音识别软件系统与工具包软件激增。其中包括Kaldi[1]、ESPNet[2]、OpenSeq2Seq[3]和Eesen[4]。经过过去十年的发展,这些框架已经从传统的基于隐马尔可夫模型(Hidden Markov Models,HMM)和高斯混合模型(Gaussian Mixture Models,GMM)发展到基于端到端的神经网络模型。许多当前的ASR工具包都不是基于声音单位(phonemes)的而是使用基于图形单位(graphemes)的端到端声学建模。本文章所介绍的ASR工具包也是如此。产生这样的转变主要有以下两方面原因:首先,端到端模型十分简单;其次,此模型与HMM/GMM系统之间原有的精确度差距正在急剧缩小。
C++是当前世界上第三广泛使用的编程语言,能够完全控制高性能任务关键型系统的所有资源。更重要的是,C++中所具有的静态数据类型可以在对大规模程序进行编译时捕捉所有协议不匹配错误(contract mismatches)。不仅如此,事实上几乎所有编程语言都可以轻松调用本地库(native libraries)。尽管在机器学习领域采用C++语言会遇到一定的困难,例如在主流框架里缺少经过完善定义的C++应用程序编程接口(API)以及在工作中C++几乎都被应用于关键性能组件方面而不是机器学习方面,由于常用语言的不同可能导致的学习成本增加等问题。但是随着机器学习代码库变得愈加庞大,在脚本语言与C++之间来回切换也变的愈发困难且容易出错。与此同时,随着现代C++的发展,只要有足够的库支持C++语言的编程速度和脚本语言的编程速度之间已经没有太大的差距。在本文中,我们将介绍第一款完全由C++语言开发的开源语音识别系统。
我们利用现代C++语言对机器学习系统进行的设计可以在不牺牲编程简易度的情况下保持软件的高效率与高可扩展性。在本工作中,我们主要将聚焦于例如训练时间、解码速度与可扩展性等ASR系统的技术方面。
接下来,我们将在第二节讨论wav2letter++的具体设计;在第三节大致讨论其他现存主要的开源系统;并在第四节中将这些系统与我们的系统进行比较。
2.设计
wav2letter++的设计主要需要满足三项需求。首先,工具包必须可以在包含数千小时语音数据的数据库中高效的训练模型。第二,必须能尽量简单地合并与表达新的网络结构和损失函数,尽可能简化其他代码操作。第三,从模型研究到模型部署的路径应该在保证研究的灵活性的基础上尽量做到简洁、直白并尽可能减少对新代码的需求。
2.1ArrayFire张量库
我们之所以采用ArrayFire作为张量操作的库主要是有以下几个原因:首先,ArrayFire是一种可以执行多种后端包括CUDA GPU后端和CPU后端的已经经过了高度优化的张量库。其次,ArrayFire使用即时代码生成技术(just-in-time code generation,也被称为惰性编译技术,lazy evaluation)来将数条简单的操作合并成一条内核调用,这可以加快内存带宽限制操作的执行速度并减少峰值内存的使用时间。另一个ArrayFire的重要特点是它具有简单的阵列构建与操作界面。与其他同样支持CUDA的C++张量库相比,ArrayFire界面不那么冗长且更少的依赖C++特性。
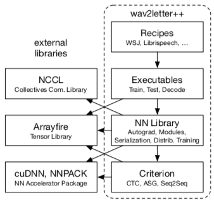
图1 wav2letter++库结构
2.2数据准备与特征提取
我们的特征提取支持多种音频文件格式(例如wav、flac.../mono、stereo/int、float)和数种特征类型,包括原始音频、线性可扩展功率谱、log-Mels(MFSC)和MFCC等。我们使用FFTW库来计算离散傅里叶变换。wav2letter++的数据加载过程是先进行动态特征计算,再进行网络评估,再加上完全端到端管道可以以单二进制文件运行,这让搜索替代特征更加简单,并使得本设计允许动态数据扩充,让模型部署变得更加简单。为了在训练模型时提高效率,我们采取并行异步的方式来加载和解码音频文件以及计算特征。对于我们已经尝试过的模型与批量大小来说,花费在数据加载上的时间是可以忽略不计的。
2.3模型
我们支持数种端到端模型。每个模型分别由“网络”和“标准”两部分组成。“网络”部分是只与输入有关的函数而“标准”部分是与输入和靶转录(target transcription)都有关的函数。与“网络”部分总是有参数不同,“标准”部分的函数并不一定有参数。这种抽象概念允许我们可以很轻松的利用相同的训练管道训练不同的模型。支持的标准包括基于神经网络连接的时序分类(Connectionist Temporal Classification,CTC)[7],原始wav2letter的AutoSegCriterion(ASG)[8],和拥有注意力算法的序列到序列模型(S2S)[9,10],其中CTC标准没有参数而ASG和S2S模型都包含可被学习的参数。与此同时,我们注意到由于像ASG和CTC这样的损失函数可以在C++中被高效使用,添加新的序列标准变得十分简单。我们同样兼容支持大量网络框架与激活函数,这里就不再一一列举。
我们用更高效的cuDNN算法扩展了核心ArrayFire CUDA后端,在cuDNN提供的众多程序中主要使用1D和2D卷积以及RNN程序。由于使用的网络库提供动态图型构造与自动微分功能,我们不用费多大劲就能进行类似新建层这样的基本操作。后文将举出一个例子展示如何建立与训练一个拥有二进制交叉熵损失的一层MLP(如图2),以此来论证C++界面的简易性。

图2 例:由二进制交叉熵和SGD训练的单隐藏层MLP,使用自动微分。
2.4训练与扩展
我们的训练管道为使用者使用不同的特征、框架与优化参数进行实验提供了最大程度的灵活性。训练程序可以在三种模式下运行:-train(平启动(flat-start)训练),continue(从检查点位置继续)和fork(例如转移学习)
此设计支持标准优化算法包括SGD和其他常用的基于梯度的优化器。我们通过数据并行同步SGD将wav2letter扩展为一个更大的数据库。使用英伟达多GPU通信库(NVIDIA Collective Communication Library,NCCL2)实现进程内通信。
为了尽可能减小进程间等待时间并提升单一进程工作效率,我们会在建立训练批次前对数据库中的数据按输入长度进行分类。
2.5解码
wav2letter++使用的解码器是经过数次提升效率优化的柱状搜索解码器,与文献[13]使用的相同,包含了来自语言模型与词语插入项的限制。解码器接口接收来自声学模型的输出与转换(如果相关)。我们同时为解码器设置了一个包含词语字典和语言模型的字典树。此解码器支持所有拥有解码器所需接口的语言模型,包括N元语言模型(n-gram LMs)和无状态参数语言模型(stateless parametric LM),并为N元语言模型提供基于KenLM的简易封装。
3. 相关工作
我们对其他常用开源语音识别系统做了一个简要概括,包括Kaldi[1],ESPNet[2]和OpenSeq2Seq[3]。卡迪语音识别工具包(The Kaldi Speech Recongnition Toolkit,Kaldi)目前是上述系统中出现时间最早的,它拥有一套独立式命令行工具包。Kaldi支持HMM/GMM与混合式基于HMM/NN的声学模型并包含基于电话的菜单(phone-based recips)。
端到端语音处理工具包(End-to-End Speech Processing Toolkit,ESPNet)与Kaldi之间联系很紧密,ESPNet将Kaldi用来进行特征提取与数据预处理。ESPNet一般将Chainer[15]或PyTorch[16]用作后端来训练语言模型,虽然主要用Python编写,但与Kaldi风格相同,高级工作流程采用实用脚本程序(bash scripts)编写。虽然这样便于系统组件的解耦,但同时也缺乏拥有静态类型的面向对象的编程语言所具有的类型安全、可靠性高和交互界面直观等优点。ESPNet具有同时拥有基于CTC的和基于注意力的解码译码器以及结合这两个标准的混合模型的特点。
OpenSeq2Seq与ESPNet类似,都具有基于CTC和拥有编码器解码器模型的特点,且都是用Python编写的,都使用TensorFlow作为后端而不使用PyTorch。若要处理高级工作流,OpenSeq2Seq同样依赖于调用Perl和Python脚本的实用脚本程序。OpenSeq2Seq系统的一个值得注意的特点是它支持混合精度训练。而且,ESPNet和OpenSeq2Seq支持文本到语音模型(Text-To-Speech,TTS)。
表1描述了这几个开源语音识别系统的具体情况。如表所示,wav2letter++是唯一一个完全使用C++编写的系统,它事实上可以很简单的和现存的用任何语言编写的应用程序整合到一起。由于它使用的C++语言具有静态变量且面向对象,所以它可以更好地适应大规模开发需求。在第四章中,我们可以看到它在与其他系统相对比时同样具有最大效率。与他形成对比的是类似Python这样的动态类型语言虽然可以提高原型设计的速度,但强制静态类型的缺失总是会妨碍大规模开发。
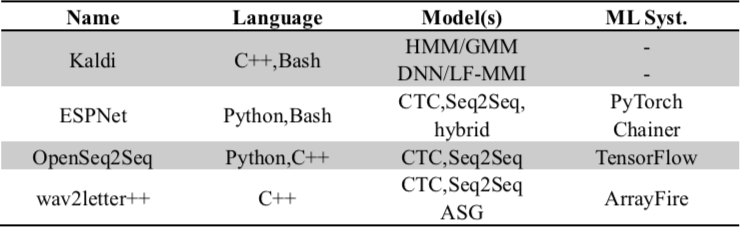
表1 主要开源语音识别系统
4.实验
在这一章我们将通过对比研究讨论ESPNet、Kaldi、OpenSeq2Seq和wav2letter++之间的表现差距,通过利用华尔街日报(WSJ)数据库中的大量词汇对自动语音识别系统进行工作评估。我们会测量训练中的平均历元时间以及平均语音解码延迟。来实验的机器硬件配置如下:每台机器配置装有八个NVIDIA Tesla V100 Tensor Core GPU的NVIDIA SXM2 模块和16GB内存,每个计算节点拥有两个Intel Xeon E5-2698 v4 CPU,总共40个核心,80个硬件线程,工作频率2.20GHz。所有机器通过100Gbps无线带宽网络进行连接。
4.1训练
我们通过扩展网络参数和增加GPU使用数量评估训练时间。我们考虑两种神经网络结构:循环结构网络,拥有三千万个参数;还有纯卷积模式,拥有一亿个参数。两种网络结构分别在图4的上下两幅图中做出了具体描述。
对于OpenSeq2Seq,我们同时考虑float32和混合精度float16训练。对于两种网络,我们使用40维log-mel滤波器组作为输入以及CTC作为标准(基于CPU的实现,CPU-based implementation)。
对于Kaldi,由于CTC训练标准在标准Kaldi菜单(recipes)中不可用,我们使用LF-MMI[19]标准。
所有模型都使用带动量(momentun)SGD进行训练。
我们使用的批次大小为每个GPU处理4条语音。每次运行限制每个GPU最多使用5个CPU核心。
图3可以提供关于训练管道主要组件的更多细节,图中展示单个GPU运行情况下在一个完整的历元时间内,对每个批次所消耗的时间进行的平均处理。
对于只有三千万个参数的更小的模型来说,就算是在单个GPU上运行wav2letter++也比第二优秀的系统快15%以上。需要注意的是由于我们使用的是8GPU设备,当我们需要进行16、32甚至64GPU实验的时候,需要引入多节点通信。但ESPNet并不支持多节点训练开箱即用(out-of-the-box)。我们通过使用PyTorch的DistributedDataParallel模式和NCCL2后端对它进行扩展。ESPNet依赖于对输入特征的预先计算,而wav2letter++和OpenSeq2Seq则由于对灵活性的需求而选择在程序运行过程中计算特征。在一些情况下,混合精度训练可以将OpenSeq2Seq的历元时间降低1.5倍以上,这项优化在未来也可以被运用在wav2letter++上。由于Kaldi的菜单在进行LF-MMI时无法同步SGD上传数据的梯度,导致每次历元花费的时间慢了20倍以上。(The Kaldi recipe for LF-MMI does not synchronize gradients for each SGD update; the per-epoch time is still more than 20x slower.)由于使用了不同的标准(LF-MMI)和优化算法导致难以进行比较,我们并没有把Kaldi包含进表4中。
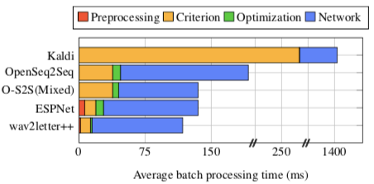
图3 训练循环中主要步骤消耗毫秒数。
4.2解码
wav2letter++包含一个用C++实现的单通柱状搜索解码器(详见2.5节)。我们将此解码器与OpenSeq2Seq和ESPNet中可获得的其他柱状搜索解码器相比较。不把Kaldi引入比较主要是因为它内置了的基于WFST的解码器并不支持CTC解码。我们利用在LibriSpeech上通过Wave2Letter+训练的完全优化的OpenSeq2Seq模型产生完全相同的,经过预先计算的数据并传输给两个解码器,这样我们就可以得到在相同模型情况下的独立的实验结果数据。由于ESPNet并不支持N元语言模型解码,我们使用的4元LibriSpeech语言模型主要用来给OpenSeq2Seq与wav2letter++提供数据。在表2中,我们主要汇报了基于LibriSpeech dev-clean的单线程解码的解码时间与峰值内存使用,验证其误码率是否低于5%并记录每个框架最低可达到的误码率。我们对超参数进行了严格的调整这样报告就可以反映在报告误码率下最大可能达到的速度。最终结果显示,mav2letter++不仅比类似的解码器表现优秀一个数量级以上,还可以大量节约内存资源。
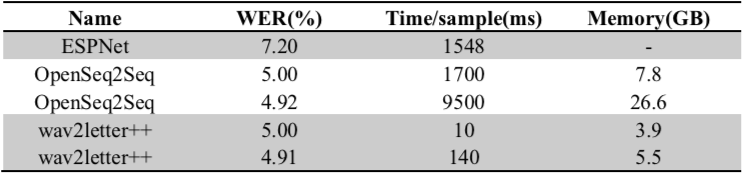
表2 基于LibriSpeech dev~clean的解码表现
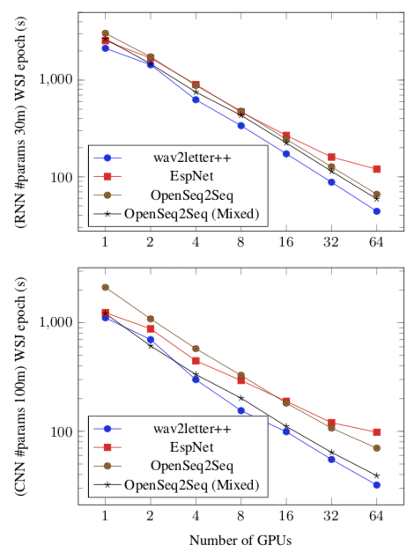
图4 训练时间对比图。上方图是一个三千万参数RNN[12],
下方图是一个一亿参数CNN[13]。
5.结论
本论文主要介绍了wav2letter:一个用于开发端到端语音识别器的高速简单系统。其框架完全通过C++实现,这使得它不仅可以高效训练模型还可以进行实时解码。我们的初步实践与其他语音框架相比展现了极大的前景,而且wav2letter++可以在未来的进一步更新中持续优化。由于它简单且可扩展的界面,wav2letter++很适合成为端到端语音识别的快速研究平台。与此同时,我们依然保留了对基于Python的ASR系统进行优化的可能性,以使其缩小与wav2letter++的差距。
.
参考文献
[1] Daniel Povey, Arnab Ghoshal, Gilles Boulianne, Lukas Burget, Ondrej Glembek, Nagendra Goel, Mirko Han- nemann, Petr Motlicek, Yanmin Qian, Petr Schwarz, et al., “The kaldi speech recognition toolkit,” in IEEE 2011 workshop on automatic speech recognition and understanding. IEEE Signal Processing Society, 2011, number EPFL-CONF-192584.
[2] Shinji Watanabe, Takaaki Hori, Shigeki Karita, Tomoki Hayashi, Jiro Nishitoba, Yuya Unno, Nelson En- rique Yalta Soplin, Jahn Heymann, Matthew Wiesner, Nanxin Chen, et al., “Espnet: End-to-end speech processing toolkit,” arXiv preprint arXiv:1804.00015, 2018
[3] Oleksii Kuchaiev, Boris Ginsburg, Igor Gitman, Vi- taly Lavrukhin, Carl Case, and Paulius Micikevicius, “Openseq2seq: extensible toolkit for distributed and mixed precision training of sequence-to-sequence mod- els,” arXiv preprint arXiv:1805.10387, 2018.
[4] Yajie Miao, Mohammad Gowayyed, and Florian Metze, “Eesen: End-to-end speech recognition using deep rnn models and wfst-based decoding,” in Automatic Speech Recognition and Understanding (ASRU), 2015 IEEE Workshop on. IEEE, 2015, pp. 167–174.
[5] James Malcolm, Pavan Yalamanchili, Chris McClana- han, Vishwanath Venugopalakrishnan, Krunal Patel, and John Melonakos, “Arrayfire: a gpu acceleration plat- form,” 2012.
[6] Matteo Frigo and Steven G. Johnson, “The design and implementation of FFTW3,” Proceedings of the IEEE, vol. 93, no. 2, pp. 216–231, 2005, Special issue on “Pro- gram Generation, Optimization, and Platform Adapta- tion”.
[7] Alex Graves, Santiago Ferna ́ndez, Faustino Gomez, and Ju ̈rgen Schmidhuber, “Connectionist temporal classifi- cation: labelling unsegmented sequence data with recur- rent neural networks,” in Proceedings of the 23rd inter- national conference on Machine learning. ACM, 2006, pp. 369–376.
[8] Ronan Collobert, Christian Puhrsch, and Gabriel Synnaeve, “Wav2letter: an end-to-end convnet- based speech recognition system,” CoRR, vol. abs/1609.03193, 2016.
[9] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben- gio, “Neural machine translation by jointly learning to align and translate,” arXiv preprint arXiv:1409.0473, 2014.
[10] Jan K Chorowski, Dzmitry Bahdanau, Dmitriy Serdyuk, Kyunghyun Cho, and Yoshua Bengio, “Attention-based models for speech recognition,” in Advances in neural information processing systems, 2015, pp. 577–585.
[11] Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer, “cudnn: Efficient primitives for deep learn- ing,” arXiv preprint arXiv:1410.0759, 2014.
[12] Awni Hannun, Carl Case, Jared Casper, Bryan Catan- zaro, Greg Diamos, Erich Elsen, Ryan Prenger, San- jeev Satheesh, Shubho Sengupta, Adam Coates, et al., “Deep speech: Scaling up end-to-end speech recogni- tion,” arXiv preprint arXiv:1412.5567, 2014.
[13] Vitaliy Liptchinsky, Gabriel Synnaeve, and Ronan Col- lobert, “Letter-based speech recognition with gated con- vnets,” CoRR, vol. abs/1712.09444, 2017.
[14] Kenneth Heafield, “Kenlm: Faster and smaller language model queries,” in Proceedings of the Sixth Workshop on Statistical Machine Translation. Association for Com- putational Linguistics, 2011, pp. 187–197.
[15] Seiya Tokui, Kenta Oono, Shohei Hido, and Justin Clay-
ton, “Chainer: a next-generation open source frame- work for deep learning,” in Proceedings of workshop on machine learning systems (LearningSys) in the twenty- ninth annual conference on neural information process- ing systems (NIPS), 2015, vol. 5, pp. 1–6.
[16] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer, “Au- tomatic differentiation in pytorch,” 2017.
[17] Mart ́ın Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, San- jay Ghemawat, Geoffrey Irving, Michael Isard, et al., “Tensorflow: a system for large-scale machine learn- ing.,” in OSDI, 2016, vol. 16, pp. 265–283.
[18] Douglas B Paul and Janet M Baker, “The design for the wall street journal-based csr corpus,” in Proceedings of the workshop on Speech and Natural Language. Associ- ation for Computational Linguistics, 1992, pp. 357–362.
[19] Daniel Povey, Vijayaditya Peddinti, Daniel Galvez, Pe- gah
Ghahremani, Vimal Manohar, Xingyu Na, Yim- ing Wang, and Sanjeev Khudanpur, “Purely sequence- trained neural networks for asr based on lattice-free mmi.,” in Interspeech, 2016, pp. 2751–2755.



 公司市政厅也有类似的功能。你有员工和高级管理人员,而不是官僚或官员,而不是公民。公司市政厅不太可能产生辩论或引发愤怒的言论,但它为领导层提供了接触所有员工的机会。公司市政厅的主要目的是让每个人都在同一页面上了解整个组织。
公司市政厅也有类似的功能。你有员工和高级管理人员,而不是官僚或官员,而不是公民。公司市政厅不太可能产生辩论或引发愤怒的言论,但它为领导层提供了接触所有员工的机会。公司市政厅的主要目的是让每个人都在同一页面上了解整个组织。
 伟大的团队——能够带来非凡成果的团队——具有某些特征。企业可以在创建团队以实现目标时学习和应用它们。例如,如果您知道成功的团队依赖于有效的协作,您可以为您的团队配备工具来帮助他们更好地协作。这比相信一群随机聚集的人会以某种方式取得成功要好得多。
伟大的团队——能够带来非凡成果的团队——具有某些特征。企业可以在创建团队以实现目标时学习和应用它们。例如,如果您知道成功的团队依赖于有效的协作,您可以为您的团队配备工具来帮助他们更好地协作。这比相信一群随机聚集的人会以某种方式取得成功要好得多。

 就整个公司而言,
就整个公司而言,