
深度学习
Deep Learning
原作者:Yoshua Bengio、Ian Goofellow、Aaron Courville等
原文发表于MIT网站:https://www.deeplearningbook.org
第一章:介绍
发明家们一直梦想着创造可以思考的机器。古希腊神话中就描述过智能物品例如会动的活的雕像和随叫随到的装满食物与饮品的餐桌。
从第一次被构想出来开始到第一台可编程计算机(Lovelace,1842)问世的一百多年间,人们一直想知道它是否可以像人一样具有智慧。如今,人工智能(artificial intelligence,AI)领域已经是一个拥有许多实用程序与活跃着研究课题的蓬勃发展的领域。我们期待着可以进行自动化常规劳动、理解语言与图片,进行医学诊断以及辅助基础科研工作的职能软件的诞生。
在人工智能发展的早期阶段,该领域通常用来快速解决那些人类智力上难以解决的,但可以用正式的数学规律描述的,对机器来说比较直观的问题。对于人工智能来说真正的挑战是那些对人来说很容易执行但却很难正式表述的事情。比如那些我们可以自动感觉到或根据直觉解决的问题,像语音与面部图像识别。
这本书就是关于这些更依赖直觉的问题的解决方法。这一解决方法允许电脑从经验中学习并依据概念层次理解世界,其中每一个概念都是依据与它相关的其他更简单的概念定义的。通过整合从经验中学到的知识,这种方法不再需要人类操作员将电脑所需的所有知识一一正式写入电脑。概念层次允许电脑通过搭建简单概念来学习复杂的概念。如果我们画出这些概念是怎样一个一个搭建在一起的,这幅画的层数回非常多,会非常深(deep)。因此,我们将这种方法称为人工智能深度学习(AI deep learning)。
许多早期的人工智能成功案例发生在相对无菌(sterile)和正规的环境下,且不需要电脑拥有过多的关于这个世界的知识。例如IBM的深蓝国际象棋系统在1997年打败了世界国际象棋冠军Garry Kasparov。国际象棋当然只是一个非常简单的世界,只包含64个位置坐标和32个只能以固定方式移动的棋子。设计一套成功的国际象棋策略是一个了不起的成就,但是这个挑战的难点并不在于向电脑描述相关概念。国际象棋完全可以通过几条简明的正式规则来描述,而且以前的编程人员以及提供了相关代码。
讽刺的是,抽象而正式的任务是人类最困难的思维任务之一,但对电脑来说,这是最简单的任务之一。电脑很早以前就可以战胜人类最强的国际象棋选手,对于识别物体与语音着了任务来说,但直到近些年才与普通人的能力相当。一个普通人的日常生活涉及到巨量关于这个世界的知识,而这些知识中又有很大一部分是主观的、直觉的,因而难以通过正式语言表达。电脑需要捕捉相同的知识才能以智慧的方式运行。人工智能领域最大的挑战之一就是如何让电脑捕捉到这种非正式知识。
有几个人工智能项目试图用硬代码的方式将关于这个世界的知识用正式语言表示。电脑可以自动通过逻辑推理规则推理这些正式语言中的语句。这正是被称为基于知识的人工智能算法。这些项目中没有任何一个项目真正成功。其中最有名的项目是Cyc(Lenat and Guha,1989).Cyc是一个推理引擎,一个用一种名叫CycL的语言写成的数据库。这些语句通过人类监督员人工写入。这是一个很繁琐的进程。工作人员得费很大力来创造足够复杂以精确描述这个世界的正式规则。例如,Cyc理解不了:“一个叫Fred的人在早上剃胡子”这样的故事(Linde,1992)。它的推理引擎在这个故事里发现了一处矛盾:它知道人类没有电动部分,但由于Fred正拿着一个电动剃须刀,因此它相信正在剃胡子的Fred作为一个整体拥有电动部分。由此,它问在Fred在剃胡子的时候Fred还是不是人类。
依靠硬代码知识的系统还面对另一个问题,AI系统需要自行从原始数据中提取特征获得知识的能力,这种能力被称为机器学习(machine learning)。机器学习的引入允许电脑解决包含了真实世界知识的问题并做出看起来主观的决定。一个简单的机器学习算法叫做逻辑回归(logistic regression),这种算法可以做出是否建议进行剖腹产的决定(Mor-Yosef et al.,1990)。另一个简单的机器学习算法名叫单纯的贝叶斯(naïve Bayes),它可以从垃圾邮件中分辨出有用的邮件。
这些机器学习算法的表现很大程度上依赖于它们被给予的数据的表述方式(representation)。例如当逻辑回归被用于给出关于剖腹产的建议时,AI系统并不直接检查病人的身体状况,而是需要医生告诉系统几条相关信息,例如是否有子宫疤痕等。每一条包含着对患者的描述的信息被称为特征(feature)。逻辑回归算法将会学习每一条患者的特征与不同结果之间只如何关联起来的。然而,这种算法却无论如何也无法改变特征的定义方式。如果逻辑回归算法得到的是一张患者3D核磁共振影像作为输入,而不是医生的正规报告,那此算法将无法做出有用的判断,毕竟核磁共振影像中每一个单一体素的状态和任何可能发生在分娩过程中的难题之间都几乎没有相关性。
这种对表述方式的依赖普遍存在于电脑科学、甚至是日常生活中。在电脑科学领域,如果需要搜索的数据集能够被智能地结构化与索引,那么搜索的效率可以以指数级提升。人们可以简单地进行阿拉伯数字计算,而对于罗马数字计算则要多花一些时间。显然,表述方式的选择对于机器学习算法的表现有着巨大的影响。图1.1展示了一个简单的视觉例子。
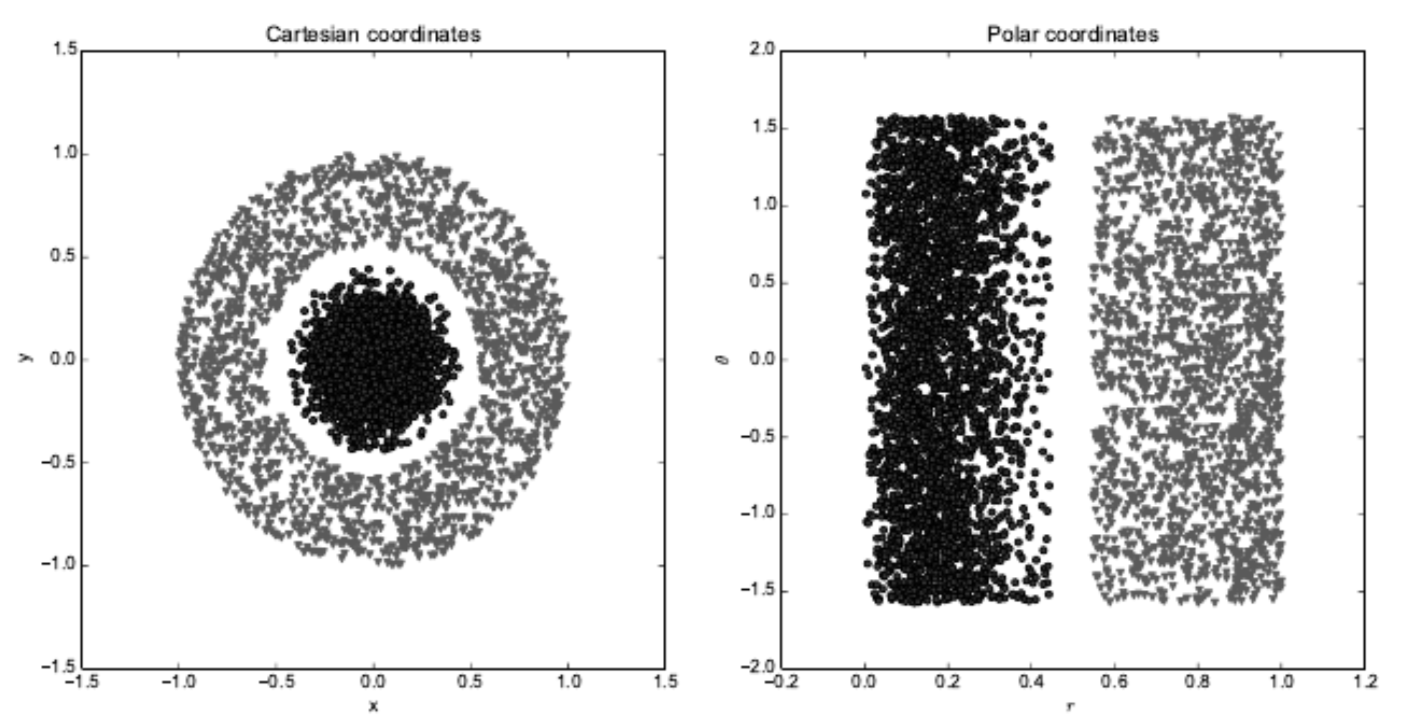
图1.1 不同的表述方式之间的区别:假设我们想通过散点图中的一条线将两类数据分开。 对于左图来说,由于我们使用卡尔迪坐标系表达数据,导致这一任务不可实现。 而对于右图,我们通过极坐标表达数据又使得这一任务变得简单直接。
许多人工智能任务都可以通过为简单的机器学习算法提供设计正确的可提取的特征集来解决。例如音高特征就是在发言人识别中一个非常有用的声音特征。音高的定义可以被正式指明——它是频谱图中最低频率的主峰。之所以说音高特征在发言人识别方面很有用,是由于它是由声道的大小决定的,这样一来就可以利用这一特征清晰分辨发言人是男人、女人还是小孩。
然而,对于很多任务来说我们本身就不知道该提取什么特征。例如,假设我们想写一个可以从图片中识别汽车的程序。因为我们都知道车有轮子,所以我们或许可以用是否有轮子作为特征。然而很可惜,通过图像像素值来描述轮子长什么样子是十分困难的。一个轮子本身具有的几何形状非常简单,但它的图像可能因为投射在轮子上的阴影、阳光照耀下轮子金属部件的反光、不同汽车的不同挡泥板或汽车前景中的遮掩了部分轮胎的物体等其他要素变得非常复杂。
这个问题的解决方法之一就是不仅利用机器学习来发现表述方式与输出之间的映射,同时也要发现表述方式本身。这种方法被称为表述方式学习(representation learning)。通过学习得来的表述方式得到的表现结果常常比手工设计的表述方式得到的表现结果更好。这种方法同样让AI系统可以在只需要非常少人工干预的情况下可以快速适应新的任务。一套表述方式学习算法可以在几分钟内为一个简单的任务发现一组高效的特征,或而对于复杂的任务则要话费几小时到几个月。为一个复杂任务人工设计特征需要耗费大量的时间与精力,甚至可能需要整个研究人员群体花费几十年时间。
表述方式学习算法中一个比较经典的例子是自动编码器(autoencoder)。一个自动编码器结合了一个用来将输入数据转化为不同表述方式的编码器(encoder)函数和一个用来将新的表述方式转变回原始数据的解码器(decoder)函数。自动编码器被训练为当输入数据运行通过编码器和解码器时尽可能不损失信息量,同时让新的表述方式拥有多种良好特性。
在设计特征或学习特征的算法时,我们的目标通常是分离那些可以解释观察数据的变化因素(factors of variation)。在本书中,我们用“因素”这个词简单的指独立的影响源,这些因素通常不会用乘法进行合并。这种因素通常不是可以直接被观察到的量,但它们的存在方式可能是未被观察到的物体或是作用在可被观察到的量上的现实世界中的力,也可能是人脑中可以为被观察数据提供有用的简化解释或推断其原因的概念。它们可以被想成帮助我们理解数据的丰富的可变形的抽象概念。在分析一条语音数据时,变化因素包括:发言人的年龄与性别、发言人的口音以及发言人说的字。当分析一辆车的图片时,变化因素包括车的位置、颜色、使用年龄和阳光下的反光。
在许多现实世界人工智能应用程序中困难的主要来源是,许多变化因素可以影响我们能观察到的每一条独立数据。在一张红车图片中的一个独立像素在晚上可能非常接近黑色而汽车轮廓的形状取决于观察的角度。大多数应用程序要求我们理清(disentangle)变化因素并抛弃我们不在乎的部分。
当然,从原始数据中直接提取如此高级而抽象的特征可能是非常困难的。这些变化因素中的许多因素,例如发言者的口音,只能通过非常复杂的,近乎人类层面的数据理解进行识别。当获得一个表述方式几乎与直接解决原始问题一样困难时,乍一看表述方式学习似乎并不能帮到我们。
深度学习(deep learning)通过用其他更简单的表述方式来表示表述方式。 解决了表述方式学习中的核心问题。深度学习让电脑通过更简单的概念来搭建复杂的概念。图1.2展示了深度学习系统是如何通过组合例如角和轮廓线等简单的概念来表示“一张人类的图片”这一复杂概念的,其中角和轮廓线等概念也是根据边缘定义的。
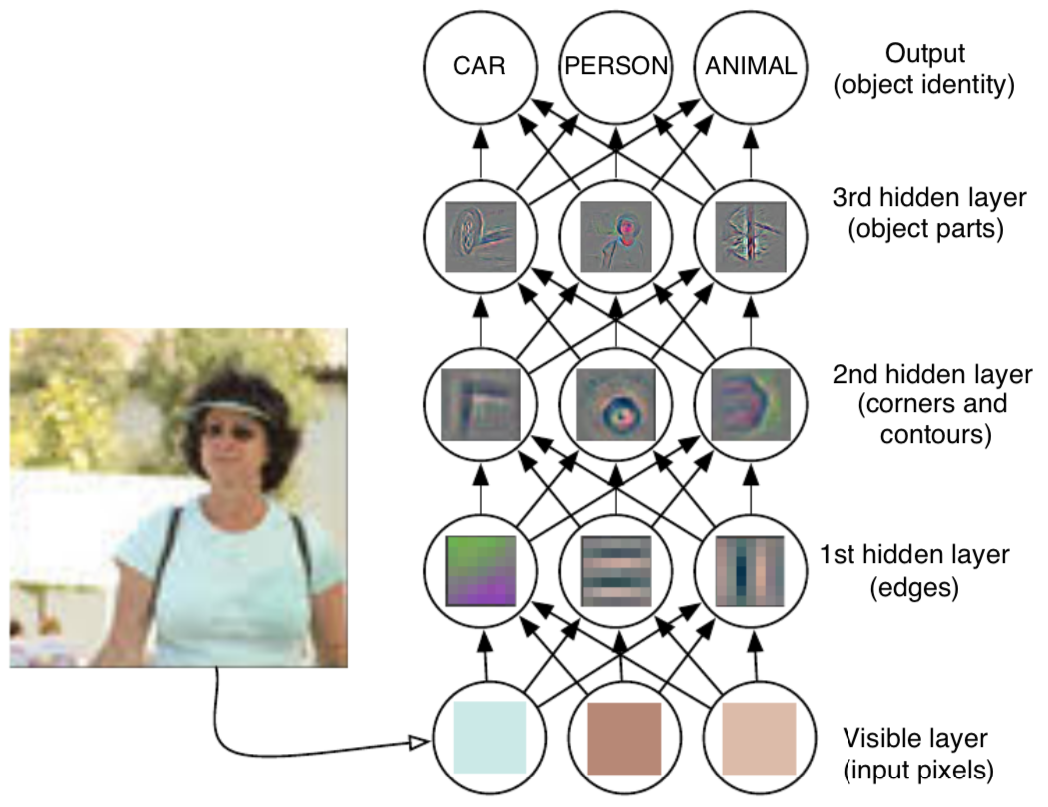 图1.2:一个深度学习模型举例:对电脑来说理解原始感觉输入数据的意义是十分困难的,比如这张图像就表示为像素值的集合。将一组像素映射到一个对象标识的函数非常复杂。如果想要直接解决问题,直接学习或估计这个映射似乎是不可能的。深度学习通过将所求的复杂映射分解成一系列嵌套的简单映射解决了这一问题,而每一个简单映射都由模型的不同层进行描述。输入展现在可视层(visible layer),之所以这么命名是因为这一层包含的变量是我们可以观察的。然后是一系列隐藏层(hidden layers)用来从图像中一步一步的提取抽象特征。这些层之所以被命名为“隐藏层”是因为它们的值不会在数据中被给出,且模型必须判断哪些概念是对解释观察到的数据间的关系有帮助的。这里的图片是对隐藏层中的特征类型进行了可视化处理后显示的图形。在给定像素的情况下,第一层可以通过比较相邻像素的亮度很轻松的识别出边缘。基于第一隐藏层对于边缘的描述,第二隐藏层可以很简单的通过识别边缘的集合搜索到角和扩展轮廓。基于第二隐藏层依据角和轮廓对图片的描述,第三隐藏层可以通过搜索特定的角和轮廓的集合检测此集合属于那个特定物体的那个部分。最后,对图像内对象所包含的部分形态的描述可以被用来识别图像内的具体对象。此图片由Zeiler和Fergus(2014)授权提供。
图1.2:一个深度学习模型举例:对电脑来说理解原始感觉输入数据的意义是十分困难的,比如这张图像就表示为像素值的集合。将一组像素映射到一个对象标识的函数非常复杂。如果想要直接解决问题,直接学习或估计这个映射似乎是不可能的。深度学习通过将所求的复杂映射分解成一系列嵌套的简单映射解决了这一问题,而每一个简单映射都由模型的不同层进行描述。输入展现在可视层(visible layer),之所以这么命名是因为这一层包含的变量是我们可以观察的。然后是一系列隐藏层(hidden layers)用来从图像中一步一步的提取抽象特征。这些层之所以被命名为“隐藏层”是因为它们的值不会在数据中被给出,且模型必须判断哪些概念是对解释观察到的数据间的关系有帮助的。这里的图片是对隐藏层中的特征类型进行了可视化处理后显示的图形。在给定像素的情况下,第一层可以通过比较相邻像素的亮度很轻松的识别出边缘。基于第一隐藏层对于边缘的描述,第二隐藏层可以很简单的通过识别边缘的集合搜索到角和扩展轮廓。基于第二隐藏层依据角和轮廓对图片的描述,第三隐藏层可以通过搜索特定的角和轮廓的集合检测此集合属于那个特定物体的那个部分。最后,对图像内对象所包含的部分形态的描述可以被用来识别图像内的具体对象。此图片由Zeiler和Fergus(2014)授权提供。
深度学习模型中最典型的例子是多层感知器(multilayer perceptron)。一个多层感知器只是一个将几组输入值映射到输出值的数学函数而已。此函数是由许多更简单的函数组成的。我们可以把不同数学函数中的每个应用想象成提供给输入数据的新的表述方式。
这种学习数据正确表述方式的想法为深度学习提供了一个视角。深度学习的另一个视角是它允许电脑学习一个多步电脑程序。表述方式的每一层都可以被理解为在并行执行完另一组指令之后的的计算机内存状态。深度更大的网络可以按顺序执行更多的指令。可以按顺序执行命令也就代表着后执行的命令可以直接参考先执行的命令的结果。根据深度学习中的这一观点,并不是层中对输入数据的表述方式中的所有必要的编码了变化因素的信息都可以解释输入数据。表述方式同样用来储存可以帮助执行可以理解输入数据的程序的状态信息。这种状态信息类似于传统计算机程序中的计数器或指针。具体地说,它与输入的内容无关,但它可以帮助模型组织数据处理。
以下有两种主流的测量模型深度的方法。 第一种方法基于评估结构时必须执行的顺序指令数量。我们可以将其视为通过流程图的最长路径,该流程图描述了如何基于输入计算每个模型的输出。就像两个等价的电脑程序,如果使用的编程语言不同,那么代码长度也会不同。两个相同的函数可能也会因为我们允许在流程图各个步骤使用的函数的不同导致流程图的深度不同。图1.3举例说明了不同语言的选择是如何导致相同的结构却具有不同的深度的。
另一个方法通常被用于深度概率模型,此方法计算的不是计算图的深度,而是概念间相互关联的图的深度。在这种情况下,由于需要计算各个概念之间的关系,整体计算的流程图的深度也许比概念本身的关系图深得多。这是因为系统对简单概念的理解可以为更复杂的概念提供精细化的信息。比如在一个AI系统观察一张有一只眼睛被遮盖在阴影里的脸的图像时,AI一开始可能认为图里只有一只眼睛,但在检测到有脸的存在时,它接着会推测另一只眼睛可能同样存在。在这种情况下,概念图只包含两层——一层是眼睛一层是脸,但如果我们对每个概念进行n次精炼估计,计算图就将包含2n层。
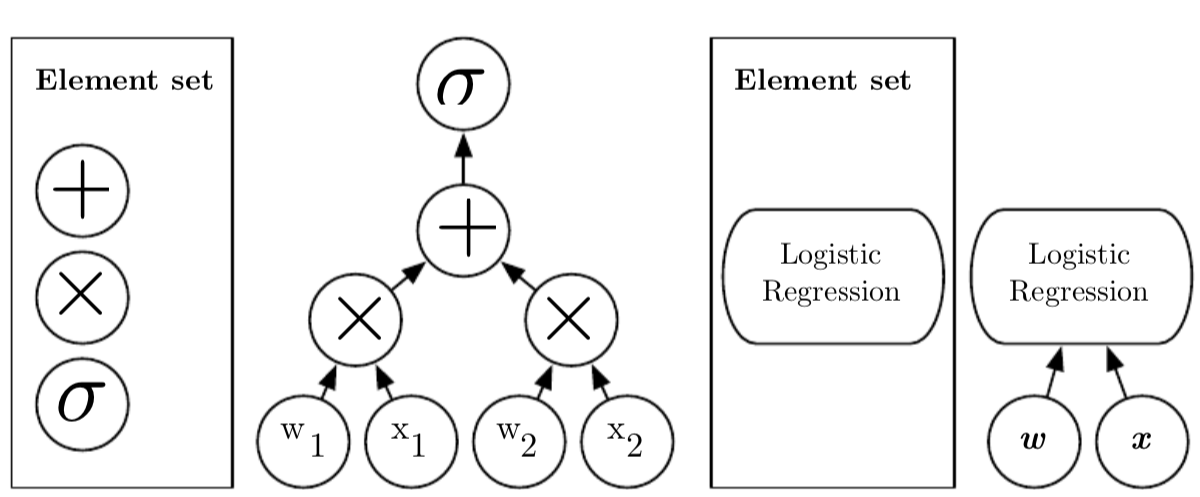 图1.3:将一个输入映射到输出的计算流图图例,其中每一个节点代表一次操作。一个流图的深度表示从输入到输出的最长路径,不过也取决于可能的计算路径的组成方式的定义。上图描述的计算是逻辑回归模型σ(ω^T x)的输出,其中σ是逻辑sigmoid函数。如果我们使用加法、乘法和逻辑sigmoid算法作为我们计算机语言的元素,那么此模型的深度为3。如果我们把逻辑回归看成一个元素,那么此模型深度为1。
图1.3:将一个输入映射到输出的计算流图图例,其中每一个节点代表一次操作。一个流图的深度表示从输入到输出的最长路径,不过也取决于可能的计算路径的组成方式的定义。上图描述的计算是逻辑回归模型σ(ω^T x)的输出,其中σ是逻辑sigmoid函数。如果我们使用加法、乘法和逻辑sigmoid算法作为我们计算机语言的元素,那么此模型的深度为3。如果我们把逻辑回归看成一个元素,那么此模型深度为1。
由于很多时候并不清楚计算图的深度和概率模型图的深度两种视角哪种相关性跟高,而且因为不同的人回选择不同的最小元素集来构建他们的图,所以综上,在描述一个框架的深度时往往有不止一个正确值,就像对于同样功能的函数代码行数往往也不止一个正确值一样。同样,也没有一个一致的标准去判断到底多深的模型深度才能叫“深”。不过你可以通过研究一个模型是否比常规机器学习模型有更大量的学习函数或学习概念来有效的判断此模型是否是深度学习模型。
综上所述,本书的主题深度学习明显是一种AI框架的搭建方式,是一类机器学习,是一种让电脑系统可以通过经验与数据进行提升的技术。根据本书作者的说法,机器学习是唯一可行的建立在复杂的现实世界环境中的AI系统。深度学习特指一种机器学习,此种机器学习通过学习表述这个世界实现了强大功能与高灵活性的结合,作为一个嵌套的多层概念与表述方式系统,每一个高级概念都由它和更简单的概念之间的关系来定义,每一个更加抽象的表述方式都依据更不抽象的表述方式进行计算描述。图1.4举例说明了不同的AI学科之间的关系。图1.5给出了每个学科的高级图表。
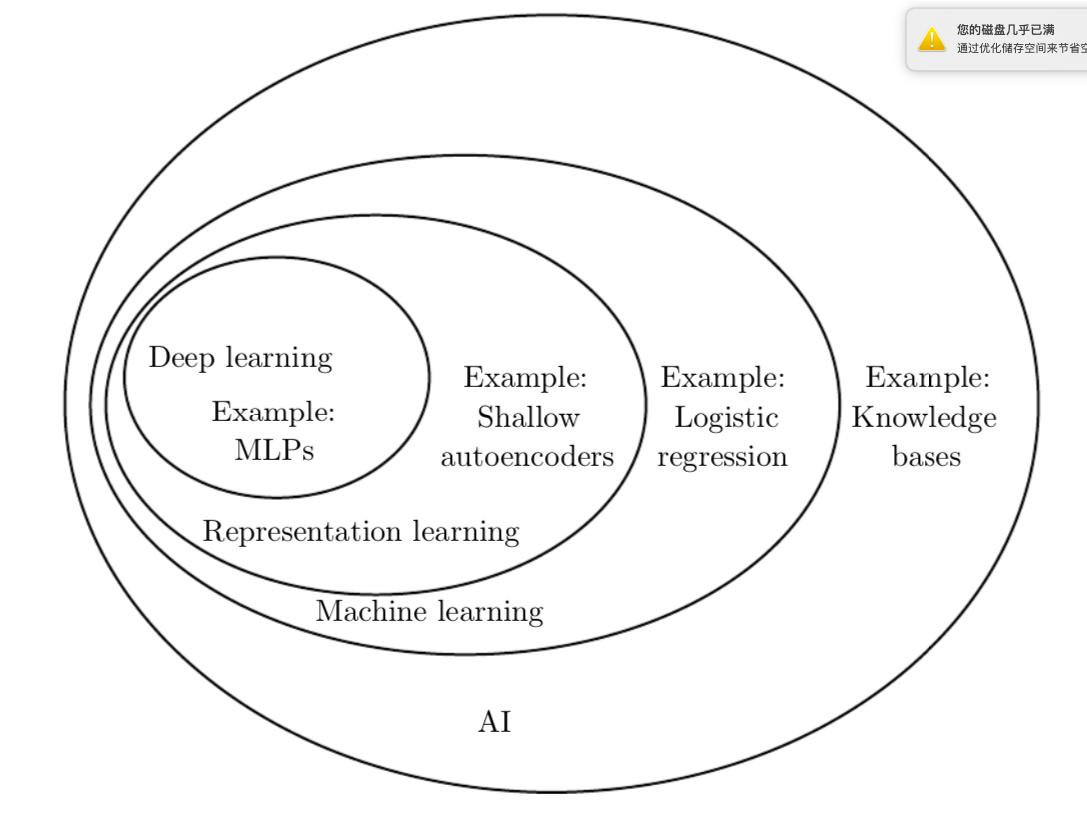 图1.4 一张展示为什么深度学习是一种表述方式学习的维恩图。同时深度学习也是一种机器学习,这种机器学习可以用于大量但不是全部AI方式。维恩图中每一节包含一个AI技术的例子。
图1.4 一张展示为什么深度学习是一种表述方式学习的维恩图。同时深度学习也是一种机器学习,这种机器学习可以用于大量但不是全部AI方式。维恩图中每一节包含一个AI技术的例子。
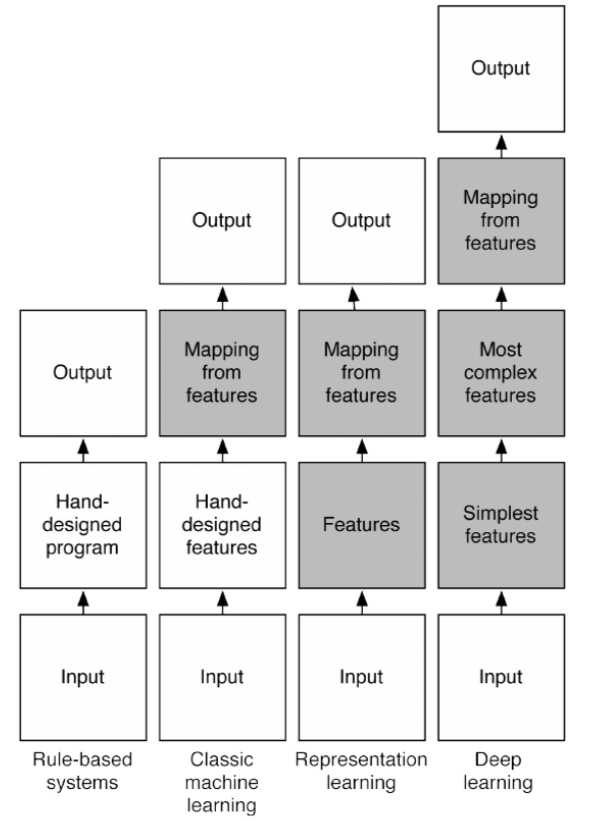 图1.5 此图展示了不同AI学科中不同AI系统部分之间是什么样的关系。阴影部分表示这部分结构可以从数据中进行学习。
图1.5 此图展示了不同AI学科中不同AI系统部分之间是什么样的关系。阴影部分表示这部分结构可以从数据中进行学习。
1.1谁应该读这本书
这本书对各种各样的读者来说都是有用的,但我们在写这本书时主要考虑两类主要目标读者。其中一类读者是学习机器学习的大学生,包括即将从事与深度学与人工智能研究相关工作的群体。另一类目标人群是没有机器学习或统计学背景,但想快速获取相关知识并在他们的产品或平台上开始使用深度学习软件工程师群体。软件工程师可以从事的大量产业都可以利用到深度学习,而且很多产业对机器学习的使用也被证明是成功的,例如电脑视觉、语音和自动处理、自然语言处理、机器人技术、生物信息学和化学、电子游戏、搜索引擎、在线广告和经济学等。
为了能适应不同群体读者的需求,这本书被组织成三部分。第一部分介绍了基础数学工具与机器学习概念。第二部分将描述最成熟的深度学习算法,这些算法的问题基本已被解决。第三部分将描述被普遍认同将在未来深度学习研究中起重要作用的更多实验性想法。
读者可以根据自身情况自行选择需要阅读的部分,跳过哪些不重要的部分。比如哪些熟悉线性代数、概率论和基础机器学习概念的读者可以跳过第一部分,而那些只想使用一个工作系统的读者只需要阅读第二部分。
我们假设所有读者都具有电脑科学背景。我们假定读者熟悉编程工作,对计算性能问题都有一个基础的了解,知道复杂性理论,懂得入门级微积分并了解一些图形理论的术语。
1.2深度学习领域的历史趋势
理解深度学习最简单的方法就是联系上下文。我们并不是把深度学习的历史事无巨细的讲出来,而是确认几个关键趋势: ·深度学习有非常久远且丰富的,但在过去它有许多名字,分别反映了不同的哲学观点,而且在受欢迎程度上有起有伏。 ·随着可用的训练数据的增加,深度学习已经变得更加有用。 ·随着深度学习使用的硬件与软件基础架构的提升,其规模也与日俱增。 ·随着时间的推移,深度学习的精确性不断提高,变得越来越复杂的应用程序也就不成问题。
1.2.1神经网络历史上的天才们
我们认为这本书的许多读者都应该听说过深度学习是一种激动人心的新技术,并且会对看到在介绍这样一种新兴领域的书中提到历史感到惊奇。事实上,深度学习有一段长而丰富的历史。深度学习只是看起来很新,因为与它现在的受欢迎程度相比,深度学习以前可以说是默默无闻了许多年,而且还有许多不同的名字。虽然“深度学习”这一称呼非常新,但是这一领域可以追溯到1950年代。由于受到不同研究人员与不同观点的影响,这一领域被重塑过很多次。
对深度学习的全部历史的研究超出了本教学教科书的讨论范围。不过一些基础背景对于理解深度学习还是很有帮助的。总体而言,历史上共有三次三次深度学习的发展浪潮,分别是:1940年代到1960年代,这期间深度学习被称为控制论(cybernetics);1980年代到1990年代,这期间深度学习被称为连接主义;以及从2006年开始的又一次的复苏,这一次被称为深度学习(deep learning)。详见图1.6的时间轴。
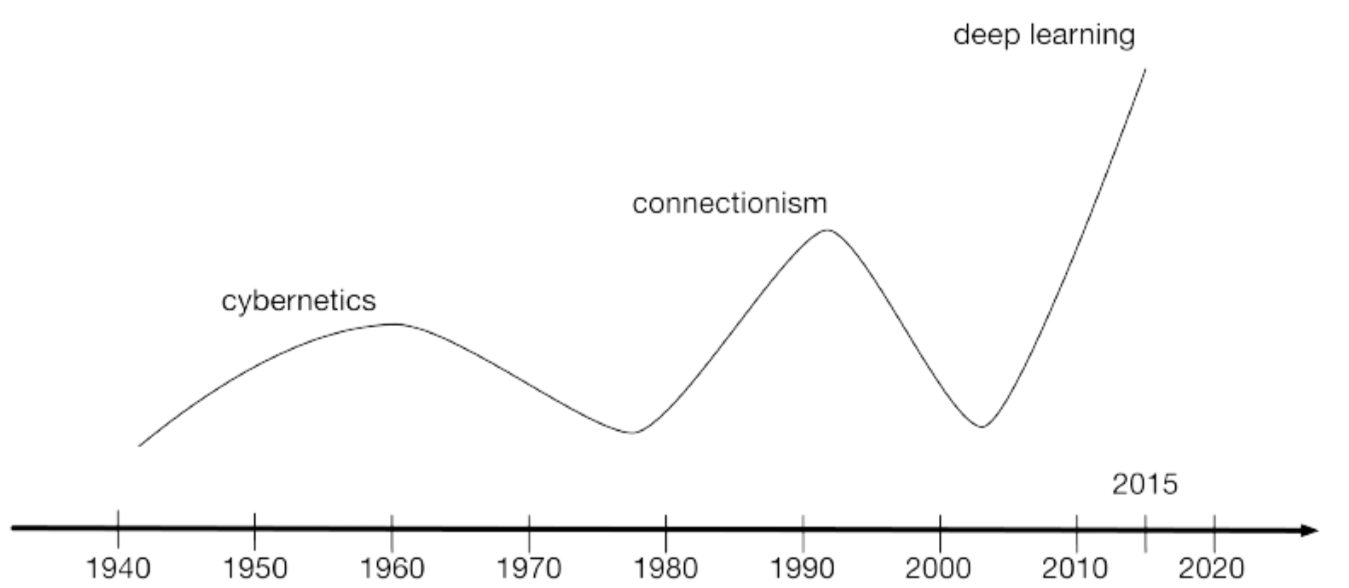 图1.6 历史上三次人工神经网络研究浪潮,从1940-1960年代的控制论开始,从只能训练一个单一神经的感知器(Rosenblatt,1958),到使用反向传播(back- propagation)(Rumelhart等人,1986a)来训练拥有一到两个隐藏层的神经网络的1980-1995年间的连接主义方法,再到现在的开始于大概2006年的深度学习浪潮(Hinton 等人, 2006; Bengio等人, 2007a; Ranzato 等人, 2007a),让我们可以训练非常深的网络
图1.6 历史上三次人工神经网络研究浪潮,从1940-1960年代的控制论开始,从只能训练一个单一神经的感知器(Rosenblatt,1958),到使用反向传播(back- propagation)(Rumelhart等人,1986a)来训练拥有一到两个隐藏层的神经网络的1980-1995年间的连接主义方法,再到现在的开始于大概2006年的深度学习浪潮(Hinton 等人, 2006; Bengio等人, 2007a; Ranzato 等人, 2007a),让我们可以训练非常深的网络
一些我们如今见到的最早的学习算法都旨在成为生物学习的计算模型,例如模拟学习过程在大脑里是如何发生或怎样才能发生的模型。因此,深度学习曾经使用过的一个名字就叫做人工神经网络(artificial neural networks,ANNs)与之相对应的对于深度学习模型的看法是,深度学习模型就是由生物学大脑启发的工程系统(可以使人类的也可以是其他动物的大脑)。对于深度学习的神经方面的看法主要是由两种观点驱动。第一个观点表明:大脑本身证明了智能行为是可行的,而建立智能的一条在观念上非常直接的方式就是对大脑运行背后的计算原理进行逆向工程并复制其功能。另一个看法认为:理解大脑和哪些构成人类智能的准则本身非常有趣,所以除了这些模型本身具有的解决工程应用难题的能力外,能够阐明基础科学问题的机器学习模型本身就很有用。
现代术语中表达的“深度学习”已经超过了神经科学视角下的当前版本机器学习模型,它需要更通用的多层组合学习准则(multiple levels of composition)。这种准则需要可以被应用到并非启发神经网络的自机器学习框架。
最早期的现代深度学习前身是神经科学观点下的简单的线性模型,此模型被设计成拥有一组n个输入值x_1……x_n,并联系输入数据与输出数据y。这种模型会学习到一组权重ω1……ω_n,并计算他们的输出ƒ(x ,ω_)=x_1 ω_1+⋯+x_n ω_n。第一次神经网络研究浪潮被称为控制论(cybernetics),见图1.6.。
McCulloch-Pitts Neuron(McCullochhe 和Pitts,1943)是一种早期的大脑功能模型。这一线性模型可以通过测试ƒ(x_ ,ω)的正负性来识别两个不同的输入类型。当然,为了使模型可以与所需要的类型的定义相符合,需要设置正确的权重,这些权重可以通过人类操作员进行设置。在1950年代,感知器(Rosenblatt,1958,1962)成为第一个可以从每一类给出的输入示例中进行权重定义学习的模型。自适应线性元素(ADALINE)和感知器可以追溯到同一时间,它只简单的返回函数值ƒ(x)本身来预测一个实数(Widrow和Hoff,1960),而且也可以从数据中学习预测这些数。
这些简单的学习算法很大程度上影响了机器学习的现代前景。ADALINE上用的适应权重的训练算法是一个名叫随机梯度下降算法(stochastic gradient descent)中的特例。稍微改良过后的随机梯度下降算法如今依然是深度学习领域中的主流算法。
感知器与ADALINE使用的基于ƒ(x,ω)函数的模型被称为线性模型(linear models)。这些模型依然是一些使用最为广泛的机器学习模型,虽然这些模型很多情况下的训练方式与最开始的训练方式并不相同。
线性模型会受很多限制。其中最出名的是这些模型无法学习异或函数,异或函数的表述方式为ƒ([0,1], ω)=1、ƒ([1,0], ω)=1和ƒ([1,1], ω)=1、ƒ([0,0], ω)=1。观察到线性系统的这些缺陷的评论员对生物学启发的学习产生了强烈的抵制(Minsky和Papert,1969)。这是在我们广阔时间线上神经网络受欢迎程度的第一次下降(图1.6)。
如今,神经科学依然被认为是深度学习研究人员的重要的灵感来源,但已经不再是深度学习领域的主导指引学科了
如今,神经科学在深度学习研究领域的重要性降低的主要原因仅仅是已经没有足够的关于大脑的信息可供我们用作指导了。为了获得大脑使用的真实算法,我们需要能够同时显示(至少)数千交互神经元的活动。由于我们做不到这一点,导致我们甚至距离理解一些最简单、已经充分研究过的大脑部分都有很长的距离(Olshausen和Field,2005)。
神经科学让我们有理由去希望一个单一的深度学习算法可以解决许多困难的任务。神经科学家已经发现,只要将大脑重新布线,将视觉信号传输到音频处理区域,雪貂可以学习用他们大脑的音频处理区域来“看”(Von Melchner等人,2000)。这一研究表明许多哺乳动物的大脑可能使用单一的算法来完成绝大多数不同任务。在这一假说出现之前,机器学习研究更为零散,自然语言处理、视觉、动作规划和语音识别分别被不同的研究者群体研究。如今,这些应用程序社区依然是分开的,但对于深度学习研究者群体来说,同时研究几个、甚至全部这些应用领域都是很正常的。
我们可以从神经科学中得出一些粗略的指导方针。只有让许多计算单元相互连接作用才能获得智能之一基础思想正是受到大脑的启发。新认知机(Fukushima,1980)介绍了一种功能强大的图像处理模型架构。此架构正是受到了哺乳动物视觉系统的启发,而后成为了我们将在9、11章中看到的现代卷积网络(LeCun等人,1998a)的基础。如今的大多数神经元网络是基于一种被称为修正线性单元(rectified linear unit)的模型神经元。这些神经元是从大量不同学科视角下开发的,其中(Nair和Hinton,2010b)和Glorot等人(2011a)引入了神经科学领域,而Jarrett等人(2009a)引入了更偏向工程方面的领域。虽然神经科学领域是灵感的重要来源,但也不必把它当作死板的教条。我们发现真实神经的计算函数与现代修正线性单元的差别很大,我们并没有发现但对神经的更深入的模拟所具有的机器学习方面的价值或解释(but greater neural realism has not yet found a machine learning value or interpretation)。同时,虽然神经科学成功启发了几个神经网络架构,但我们目前对神经科学领域的生物学习方面还不够了解,还不能为我们用来训练这些框架的学习算法提供多少指导。
媒体账号总是强调深度学习和大脑之间的相似性。要说的是,虽然深度学习研究者确实相较于其他机器学习领域(例如核心机器或贝叶斯统计)的研究者来说更喜欢提及大脑的影响,人们也不该把深度学习视作一种对大脑模拟的尝试。现代深度学习可以从很多领域获取灵感,尤其是应用数学基本原理,像线性代数、概率论、信息论和数值优化。要知道,在有一些深度学习研究人员将神经科学作为一种重要影响进行引用的同时,另一些研究者可能根本不会考虑神经科学领域。
值得注意的是从算法领域理解大脑运行方式的努力一直存在且相当活跃。这种尝试主要被称为“计算神经科学”(computational neuroscience)而且是一个与深度学习领域不同的领域,且常有研究人员在两个领域之间来回切换。深度学习领域主要关心如何搭建可以成功解决需要智能的任务计算机系统,而计算神经科学领域主要关心搭建更能精确反映大脑真实工作的模型。
在1980年代,神经网络研究的第二个浪潮很大程度上是在一个被称为连接主义(connectionism)或并行分布式处理(parallel distributed processing)(Rumelhart等人,1986b)运动中出现的。连接主义出现在认知科学的文章上。认知科学是一个跨学科的理解思维的方式,结合了多种不同层次的分析。在1980年代早期,大多数认知科学家研究符号推理模型。尽管他们很受欢迎,符号学模型依然很难准确解释大脑是如何通过神经元实现功能的。而连接主义则开始研究事实上可以基于神经元实现的认知模型,复兴了许多可以追溯到1940年代的心理学家Donald Hebb的工作思想(Hebb,1949)。
连接主义的核心观点是:大量简单的计算单元可以通过网络互联实现智能行为。这一观点同样适用于生物神经系统中的神经元和计算模型中的隐藏单元。
1980年代在连接主义运动期间出现的即可关键概念至今仍然是深度学习的核心概念。
这些概念中的一个是分布式表示,其主体思想是系统的每一个输入都应可以被数个特征表述,且每个特征都应被包含在许多可能的输入的表述中。例如我们有一个可以识别轿车、卡车和鸟且这些东西可以是红、绿或蓝色的视觉系统。表示这些输入数据的一种方法是使每个可能的出现的组合都拥有一个单独的神经元或隐藏单元。这就要求拥有九种不同的神经,而且每个神经必须独立学习关于颜色和对象标识的概念。一种改善这种情况的方法就是用分布式表示法,用三个神经描述颜色,三个神经描述对象标识。这就只需要六种神经而不是九种,且描述红色的神经可以从汽车、卡车和小鸟的图片中学习什么是红色,而不是只能从一个特定类型的对象中学习。分布式表示是本书的核心概念,在本书第16章将描述详细细节。
另一个连接主义运动的主要成就是成功利用反向传播(back-propagation)训练具有内部表述方式的深度神经网络,并广泛传播了反向传播算法(Rumelhart等人,1986a;LeCun,1987)。这个算法的受欢迎程度有起有伏,但对于本文来说,此算法是训练深度模型的主要算法。
神经网络研究的第二浪潮一直持续到了1990年代中旬。在那时,神经网络的受欢迎度又一次下降。此次低潮部分是原因是神经网络(和人工智能总体研究)没能完成各种寻求神经网络风险投资的投资者所提出的过于理想的承诺所导致的负面反应,另一部分原因则是机器学习的另一领域:核心机(kernel machines,Boser等人,1992;Cortes和Vapnik,1995;Schölkopf等人,1999)和概率图模型(graphical models,Jordan,1998)出现了一些发展。
核心机享有许多优秀理论保证。特别是,训练一个核心机是一个凸优化问题(将在第四章描述更多细节),这就代表着训练过程中可以保证能高效寻找优化模型。这让核心机非常易于“只需要工作(just work)”类型软件实现,而不需要人类操作员理解底层逻辑。很快,大多数机器学习应用程序都包含手动设计的好特点来为各个不同应用领域提供核心机。
在这段时间里,神经网络依然在一些任务上取得令人印象深刻的表现。(LeCun等人,1998b;Bengio等人2001a)。加拿大高级研究所(CIFAR)通过它的神经计算和适应性感知研究室帮助维持了神经网络研究的活力。这项目联合了多伦多大学的Geoffrey Hinton团队,蒙特利尔大学的Yoshua Bengio团队和纽约大学的Yan LeCun团队这些机器研究组。它具有多学科的特性,其中也包含神经科学家与人类和电脑视觉的专家。
此时此刻,深度网络普遍被认为是十分难以训练的。我们现在知道从1980年代就存在的算法可以很好的工作,但这在2006年前后并不明显。其中的问题可能只是简单的这些算法所需消耗的计算能力太大,当时的硬件普遍计算能力无法支持大量实验。
第三波神经网络研究浪潮开始于2006年的一项突破。Geoffrey Hinton展示了一种被称为深信网络的神经网络,这种网络可以利用一种名叫贪婪分层预训练的策略(Hinton等人,2006)进行高效训练。在16.1节中,我们将进行详细描叙。其他附属于CIFAR的研究团队很快发现这一策略可以被用于训练许多其他类型的深度网络(Bengio等人,2007a;Ranzato等人,2007a)并且可以系统性地帮助提升测试示例的泛化能力。这一次神经网络研究浪潮推广了深度学习这一术语的使用,强调了与以前有可能训练相比,训练研究人员现在已经可以训练深度神经网络以及深度的理论上的重要性(Bengio 和 LeCun, 2007a; Delalleau 和 Bengio, 2011; Pascanu 等人, 2014a; Montufar等人, 2014)。深度神经网络之所以在这段时间里能够在几个重要的应用领域取代需要手动设置参数的核心机一部分原因是因为训练核心机所需要的时间与内存与数据集大小成平方比关系,随着数据集越来越庞大,时间与内存的代价逐渐掩盖了凸优化所带来的优势。第三波神经网络浪潮一直持续到本书写作的时候,不过在这股浪潮中深度学习的研究重点发生了巨大变化。第三波浪潮开始于对新的无人监督学习技术的关注以及深度模型从小数据集中优秀的一般化能力。但现在,更多的人对更古老的监督学习算法以及深度模型利用大型标记数据集的能力更感兴趣
1.2.2不断增大的数据库规模
人么可能会疑惑,问什么深度学习在1950年代就出现了,而在近些年才被认为是一项关键技术呢。深度学习在1990年代就已经被成功的用于商业用途了,但在那个时候深度学习一般被认为是一项艺术而不是技术,是一种只有专家才会用的东西,直到近些年这种思想才被改变。诚然,想要深度学习算法表现出优秀的性能是需要一些技术的。幸运的是,随着训练数据量的增加,所需要的技能量也会随之减少。如今那些在处理复杂问题时能与人类表现相当的学习算法与1980年代那些艰难处理玩具问题的学习算法几乎相同,而我们用这些算法训练的模型在经过对深层次架构的训练的简化后,已经发生了变化。其中最重要的发展是如今我们可以为这些算法运行提供成功所需要的资源。图1.7展示了基准数据集是如何随着时间不可思议的增长的。社会的数字化趋势是此增长的重要动力源泉。随着我们在电脑上的活动越来越频繁,我们的活动也越来越多的被记录了下来。随着我们的电脑越来越多的被网络连接在一起,将这些活动记录集中起来并整理成适合机器学习应用程序的工作也就越来越简单。大数据时代(the age of“Big Data”)让机器学习更加简单,这也是因为统计估计中的关键困难——观察一小部分数据,就能很好的推广到新数据——已经被很大程度的减轻。在2015年,一条粗略的经验规则是,一个监督深度学习算法之需要大概每类5000个标记示例就可以总体实现可接受的算法表现,而在经过至少拥有1000万标签示例的数据集的训练之后其表现就与人类相当,甚至超越人类。如何降低成功所需的数据集要求是一个很重要的研究领域,特别是聚焦于我们应该如何利用无人监督或半监督学习发挥出大量无标记示例的优势。
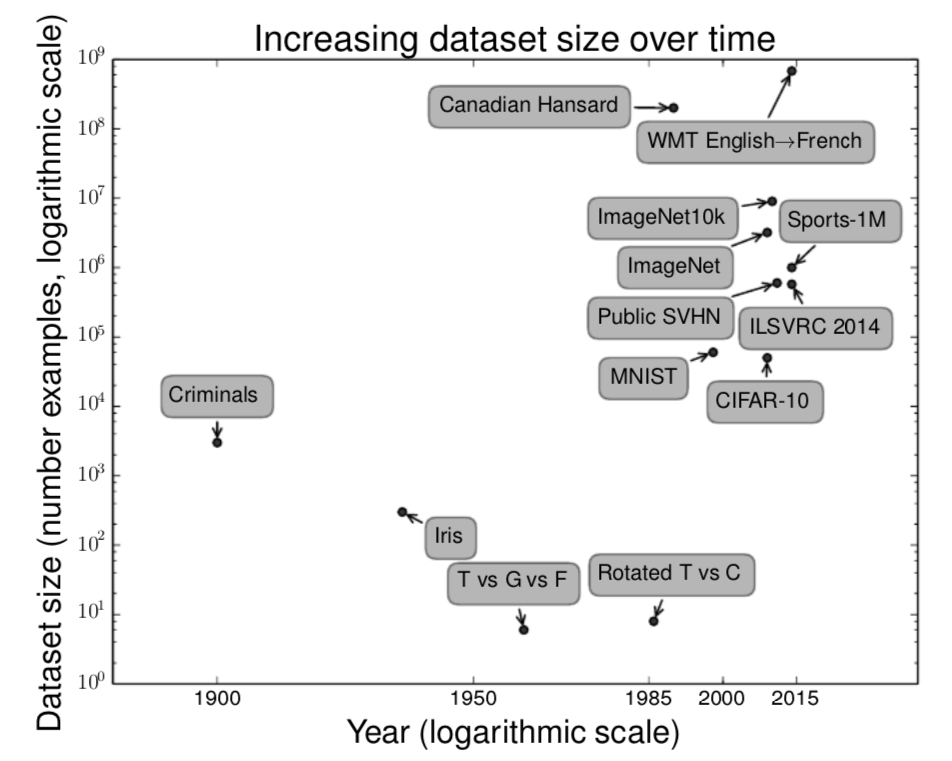 图1.7 随着时间的推移,数据集规模发生了很大提升。在1900年代早期,统计学家们通过数百甚至上千个手动编译的测量值来研究数据集(Garson,1900; Gosset,1908; Anderson,1935; Fisher,1936)。在1950到1980年代,受生物学启发的机器学习先驱通常使用很小的人工数据集,例如字母的低分辨率位图,这些位图的设计目的就是为了降低算力消耗并最终证明了神经网络可以学习特定类型的功能(Widrow和Hoff,1960;Rumelhart 等人,1986b)。在1980到1990年代,机器学习在本质上变得更加倾向统计学并且开始利用更大的包含了数万示例的数据集,例如手写数字的扫描数据集MNIST (LeCun等人,1998b)。在21世纪的前十年,更多类似CIFAR-10 (Krizhevsky和Hinton,2009)这样的更复杂的同等规模的数据集相继被制造了出来。在这十年的末期和2010年代的前半部分,明显变大的包含数十万到数千万示例的数据库完全改变了深度学习的可能性。这些数据集包含了公开的数据库Street View House Numbers (Netzer等人,2011),各种版本的ImageNet数据库(Deng等人,2009,2010a;Russakovsky等人,2014a),以及Sports-1M 数据库(Karpathy等人,2014)。在图表的最顶端,我们可以看到翻译语句数据库,例如IBM的由Canadian Hansard (Brown等人,1990)和WMT 2014 数据库(Schwenk,2014)组成的数据集就远比其他数据库规模大。
图1.7 随着时间的推移,数据集规模发生了很大提升。在1900年代早期,统计学家们通过数百甚至上千个手动编译的测量值来研究数据集(Garson,1900; Gosset,1908; Anderson,1935; Fisher,1936)。在1950到1980年代,受生物学启发的机器学习先驱通常使用很小的人工数据集,例如字母的低分辨率位图,这些位图的设计目的就是为了降低算力消耗并最终证明了神经网络可以学习特定类型的功能(Widrow和Hoff,1960;Rumelhart 等人,1986b)。在1980到1990年代,机器学习在本质上变得更加倾向统计学并且开始利用更大的包含了数万示例的数据集,例如手写数字的扫描数据集MNIST (LeCun等人,1998b)。在21世纪的前十年,更多类似CIFAR-10 (Krizhevsky和Hinton,2009)这样的更复杂的同等规模的数据集相继被制造了出来。在这十年的末期和2010年代的前半部分,明显变大的包含数十万到数千万示例的数据库完全改变了深度学习的可能性。这些数据集包含了公开的数据库Street View House Numbers (Netzer等人,2011),各种版本的ImageNet数据库(Deng等人,2009,2010a;Russakovsky等人,2014a),以及Sports-1M 数据库(Karpathy等人,2014)。在图表的最顶端,我们可以看到翻译语句数据库,例如IBM的由Canadian Hansard (Brown等人,1990)和WMT 2014 数据库(Schwenk,2014)组成的数据集就远比其他数据库规模大。
1.2.3不断增大的模型尺寸
相对于1980年代以来取得的相对较少的成功,另一个神经网络可以取得如此广泛成功的关键原因是我们如今拥有了可以运行大的多的模型的计算资源。连接主义的主要观点之一是当许多动物神经系统一起工作时,它们也能获得智能。一个单独的神经元或神经元的小规模连接并不特别有用。
生物学神经元的连接并不特别紧密。如图1.8所示,我们的机器学习模型中所拥有的每个神经元的连接量在几十年的时间里甚至和哺乳动物的大脑处于一个数量级。
如图1.9,就神经元的总体数量而言,神经元网络直到最近依然非常小。自从引入了隐藏单月,人工神经网络规模大概每2.4年翻一倍。这种增长是由拥有更大内存更快速度的电脑和更大的数据集的出现推动的。更大的网络可以以更高的精度处理更复杂的信息。这一趋势看起来似乎会持续数十年。除非新的技术为我们提供更快的扩展速度,人工神经网络在至少2050年以前都不可能拥有和人类大脑一样的神经元数量。生物神经元似乎具有比当前的人工神经元更复杂功能,也就是说生物神经元网络也许甚至比这节中描述的还要大。
回过头来看,拥有神经元比水蛭(leech)还少的神经元网络无法解决复杂的人工智能问题也就不奇怪了。就算是我们以计算系统的观点看来相当大的如今的网络,其神经系统规模都比青蛙这类相当原始的脊椎动物的神经系统规模要小。
模型规模之所以可以随着时间不断增大,是因为随着时间的推移,我们获得了更快的CPU、更先进的通用型GPU、更快的网络连接速度以及更优秀的分布式计算机软件基础设置。不断增大的模型规模是深度学习历史上最重要的趋势之一。预期这一趋势总体上在未来会很好的持续下去。
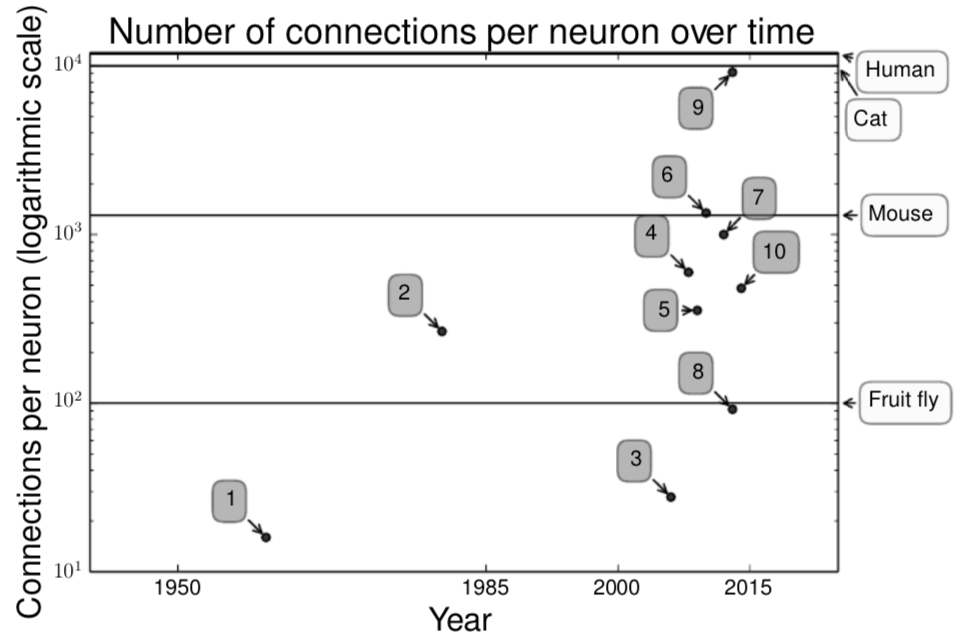 图1.8 最开始,人工神经网络中神经元间连接的数量会受到硬件能力的限制。如今,神经元间连接的数量主要是受到设计考虑因素的影响。一些人工神经网络所具有的神经元间连接数量已经接近猫的大脑,而在其他神经网络中连接数量超过类似于老鼠这样的哺乳动物已经是非常常见的事情了。即使是人脑,每个神经元的连接数也不会特别多。生物神经网络稀疏的连接意味着即使在硬件条件受限的情况下我们依然有机会制造出与生物神经网络能力相当的人工神经网络。现代神经网络比任何脊椎动物的大脑都要小得多,但是由于我们通常只会训练网络去完成一种任务,而动物的大脑却要分成不同的区域去完成不同的任务。动物神经网络规模来自维基百科(2015)。
图1.8 最开始,人工神经网络中神经元间连接的数量会受到硬件能力的限制。如今,神经元间连接的数量主要是受到设计考虑因素的影响。一些人工神经网络所具有的神经元间连接数量已经接近猫的大脑,而在其他神经网络中连接数量超过类似于老鼠这样的哺乳动物已经是非常常见的事情了。即使是人脑,每个神经元的连接数也不会特别多。生物神经网络稀疏的连接意味着即使在硬件条件受限的情况下我们依然有机会制造出与生物神经网络能力相当的人工神经网络。现代神经网络比任何脊椎动物的大脑都要小得多,但是由于我们通常只会训练网络去完成一种任务,而动物的大脑却要分成不同的区域去完成不同的任务。动物神经网络规模来自维基百科(2015)。
- Adaptive Linear Element (Widrow和Hoff,1960)
- Neocognitron (Fukushima,1980)
- GPU-accelerated convolutional network (Chellapilla等人,2006)
- Deep Boltzmann machines (Salakhutdinov和Hinton,2009a)
- Unsupervised convolutional network (Jarrett等人,2009b)
- GPU-accelerated multilayer perceptron (Ciresan等人,2010)
- Distributed autoencoder (Le等人,2012)
- Multi-GPU convolutional network (Krizhevsky等人,2012a)
- COTS HPC unsupervised convolutional network (Coates等人,2013) 10.GoogLeNet(Szegedy等人,2014a)
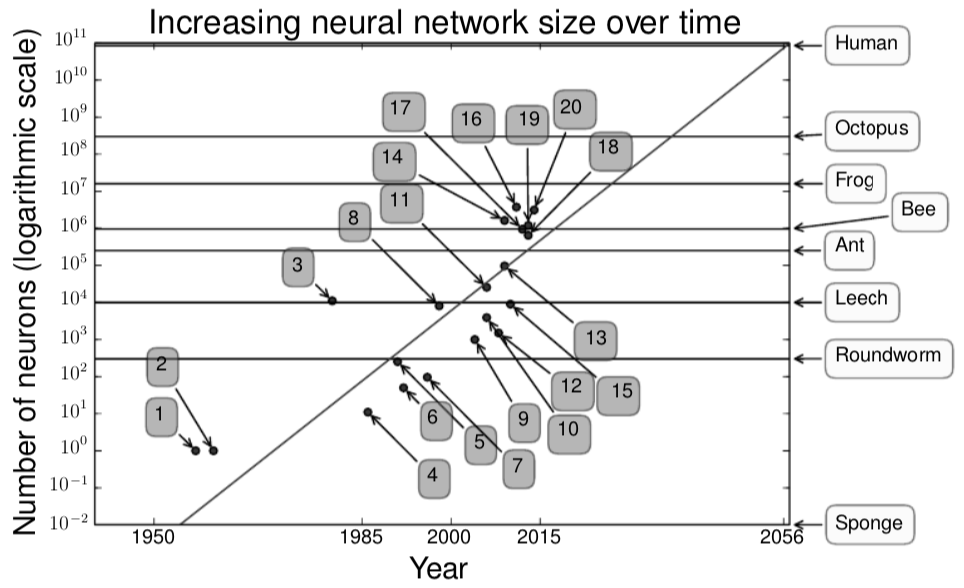 图1.9 自从引入隐藏单元,冉工神经网络规模大约每2.4年翻一番。生物神经网络规模引自维基百科(2015)。
图1.9 自从引入隐藏单元,冉工神经网络规模大约每2.4年翻一番。生物神经网络规模引自维基百科(2015)。
- Perceptron (Rosenblatt,1958,1962)
- Adaptive Linear Element (Widrow和Hoff,1960)
- Neocognitron (Fukushima,1980)
- Early backpropagation network (Rumelhart等人,1986b)
- Recurrent neural network for speech recognition (Robinson和Fallside,1991)
- Multilayer perceptron for speech recognition (Bengio等人,1991)
- Mean field sigmoid belief network (Saul等人,1996)
- LeNet-5 (LeCun等人,1998a)
- Echo state network (Jaeger和Haas,2004) 10.Deep belief network (Hinton等人,2006) 11.GPU-accelerated convolutional network (Chellapilla等人,2006) 12.Deep Boltzmann machines (Salakhutdinov和Hinton,2009a) 13.GPU-accelerated deep belief network (Raina等人,2009) 14.Unsupervised convolutional network (Jarrett等人,2009b) 15.GPU-accelerated multilayer perceptron (Ciresan等人,2010) 16.OMP-1 network (Coates和Ng,2011) 17.Distributed autoencoder (Le等人, 2012) 18.Multi-GPU convolutional network (Krizhevsky等人,2012a) 19.COTS HPC unsupervised convolutional network (Coates等人,2013) 20.GoogLeNet (Szegedy等人,2014a)
1.2.4精确性增加,应用复杂化和现实世界影响
从1980年代开始,深度学习的识别与预测能力的精准性就持续提升。此外,成功应用深度学习的领域也不断扩大。
最早期的深度模型被用于识别紧密裁剪的极小图片中的单个对象(Rumelhart等人,1986a)。从那时起神经网络可以处理的图片大小就开始不断增大。现代物体识别网络可以处理丰富的高分辨率图片且不需要将需要识别的物体沿边缘剪下(Krizhevsky等人,2012b)。类似的,最早期的网络只能识别两类对象(或在一定情况下,判断某一种对象是否存在),而现代网络通常能够识别至少1000种不同类型的对象。物体识别领域最大的竞赛是每年举办的图像软件大型视觉识别竞赛(ImageNet Large-Scale Visual Recognition Competition)。深度学习迅速崛起过程中的一个戏剧性时刻来自于一个卷积网络第一次以巨大优势赢得了这项比赛并将最先进的错误率从26.1%降到了15.3%(Krizhevsky等人,2012b)。从那时起这类比赛的赢家就一直是深度卷积网络,到目前为止,由深度学习带来的优势已经将这场比赛的最新错误率利用更深的网络下降到了图1.10中展示的6.5%(zegedy等人,2014a)。在竞赛框架之外,如今的这类错误率已经下降到了5%以下(Ioffe和Szegedy,2015;Wu等人,2015).
深度学习对语音识别领域同样也有重大影响。经过整个1990年代的提升,语音识别的错误率改善工作在大概2000年开始陷入停滞。将深度学习引入语音识别(Dahl等人,2010;Deng等人,2010b;Seide等人,2011;Hinton等人,2012a)。直接导致错误率下降近半!我们将在12.3.1中详细介绍这段历史。
深度网络同样在行人识别和图像分段方面有巨大提升(Sermanet等人,2013; Farabet等人,2013a;Couprie等人,2013)而且在交通标志分类方面产生了超越人类的表现(Ciresan等人,2012)。
与此同时,深度网络的规模、精确性以及它们所能解决的问题的复杂性也提升了。Goodfellow等人(2014d)展示了神经网络可以学习从一张图片中输出整个字符序列,而不只是识别一个单独的对象。在此之前,人们普遍相信这类学习需要对序列里的每个单独元素进行标记(Gülçehre和Bengio,2013)。从那时起,长短期记忆(the Long Short-Term Memory,LSTM),一种被设计用于建模序列的神经网络人气激增。LSTM与相关模型现在被用于建模序列(sequences)之间的关系而不仅仅是固定输入与序列间的关系。这种序列到序列的学习似乎处于另一个革命性领域的前沿:机器翻译(Sutskever等人,2014a;Bahdanau等人, 2014)。
随着神经图灵机(Graves等人,2014)的引入,这种复杂性日益增加的趋势已经被推出了合乎逻辑的结论,这是一种可以学习整个程序的网络。这一神经网络一显示在给出置乱和排序序列的情况下可以学习对数据列表进行排序。这种自我编程技术还处于初期,但是在未来,这种技术原则上可以被运用到几乎任何任务上。
深度学习的许多应用程序是高利润的,因为有足够的数据可以应用深度学习。深度学习现在被许多顶尖技术公司使用包括谷歌、微软、脸书、IBM、百度、苹果、Adobe、Netflix、NVIDIA和NEC。
深度学习也为其他科学领域做了贡献。对象识别方面的现代卷积网络提供了一个可供神经科学家研究的视觉处理模型(DiCarlo,2013)。深度学习同样在科学领域的大量复杂数据处理和提供高效预测方面提供有用的工具。这类工具可以通过预测分子相互作用来帮助制药公司设计新药(Dahl等人,2014),帮助搜索亚原子粒子(Baldi等人,2014),和自动解析用来构造人脑三维地图的显微镜影像(KnowlesBarley等,2014)。我们期待深度学习未来出现在更多科学领域中。
总的来说,深度学习是一种在过去几十年的发展中极大借鉴了我们的大脑、统计学和应用数学的机器学习方法。在近几年,由于更强大的电脑、更大的数据集和能训练更深的网络的技术的出现,深度学习在受欢迎程度和有用性上都有很大的提高。在之后的几年甚至未来的很长时间都充满了提升机器学习能力并将它引入全新领域的挑战与机遇。
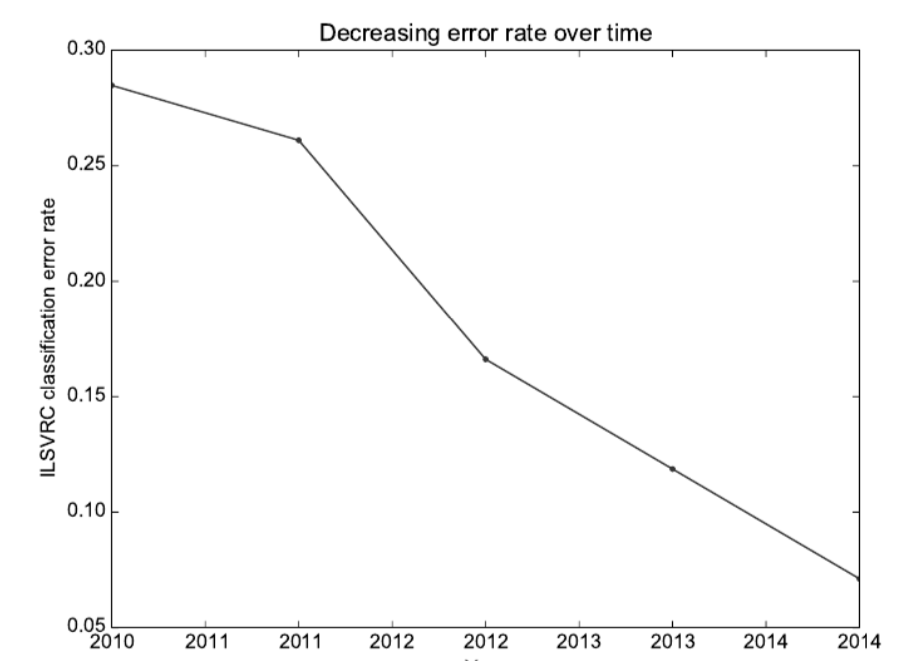 图1.10 自从深度网络达到了参加了图像处理软件大规模视觉识别竞赛的规模要求后,就持续赢得了每年的冠军,并每一次都会降低错误率。数据由Russiakovsky等人提供(2014b)。
图1.10 自从深度网络达到了参加了图像处理软件大规模视觉识别竞赛的规模要求后,就持续赢得了每年的冠军,并每一次都会降低错误率。数据由Russiakovsky等人提供(2014b)。